LSM Tree
LSMTree's are another disk based database tool, and is often compared to BTree's. BTree's are focused on making reads an efficient operation as compared to writing, and so during writing it's also an operation - LSMTree's are focused on making writes more efficient / cheaper, while allowing for reads from disk based data. There are more operations to do during a read on an LSMTree, but it's writes are extremely fast and mostly stay in-memory for any client / SDK operations, which makes it a good tool for heavy-write use cases that need durable storage
LSMTree's have 3 major components:
- The MemTable is an in memory data structure for storing K:V pairs for serving client / SDK operations
- In memory data structure usually implemented as a skip list
- Any new record is immediately written to in-memory MemTable
- Max capacity, usually is 2MB, but can be anything (within reason)
- When capacity is reached, records are flushed to disk
- 3 routines:
- Add a record to list
- Sorting records
- Find record using Binary Search
- Each MemTable has a WAL (Write Ahead Log) that sits on disk
- RAM objects are now persistent or durable - WAL helps us maintain that promise
- Append only, immutable log file, that every record operation on MemTable is appended into
- Set, Update, or Delete is appended to log
- If node goes down, WAL can be used to re-create MemTable
- Once MemTable is full and written to disk, corresponding WAL is deleted
- Finally, when a MemTable is full, it's flushed to an SSTable
- When a MemTable is flushed to disk, you take that Sorted Run and store it on disk as an SSTable
- i.e. when you want to write MemTable to disk, you store it as an SSTable
- SSTables are organized into levels with max capacities of powers
- 10MB, 100MB, etc...
- Whenever any level reaches capacity, it's Compacted into next level
- This means older records will persist on disk in older SSTables until updated
- When a MemTable is flushed to disk, you take that Sorted Run and store it on disk as an SSTable
- The flushing / cleaning up is known as Compaction
- Our garbage collection and data management process of our database
- Runs in the background to continuously merge / reorganize SSTables
- Compaction takes SSTable from filled level and merges it with SSTables in next level with overlapping key ranges
- When files are merged we:
- Re-sort keys
- Outdated records are removed
- New SSTable is created
- When files are merged we:
- API's
- GET - This should search MemTable, and then earliest to oldest levels (lowest to highest) to find the latest record
- SET - Should set it into MemTable, which updates WAL, which eventually makes into SSTable levels once capacity is reached
- DELETE - Inserts a Tombstone into the MemTable
- GET that receives a Tombstone means no record / was deleted
- When Tombstone goes down to lower SSTables it would take precedence over regular values
- SCAN - Collects all records between low_key and high_key
- GET(low_key) and iterate until iterator > high_key
- Most likely have to scan multiple SSTables at different levels
Implementation
MemTable
MemTables keep a record of the current state of any key in memory, and can serve any requests on keys in there as they're the most up to date. Once a MemTable is full it needs to get flushed, and so the MemTable ensures it's data is stored in a sorted way so the flush is optimized. Usually this is implemented using a sorted container, and realistically just needs to support reads and writes while keeping data sorted for flushing. RocksDB uses a Skip List which is a Linked List with multiple other links that you can use to skip. Skip Lists still have, on average, search without insert, and can support point and range queries effectively. Because of this setup LSMTree remove need for random disk writes which is how B-Tree would handle it
WAL
The WAL ensures durability and complete recovery can be done even during system failure - it records each transaction on a MemTable
struct WALRecord {
uint64_t sequence_number;
RecordType type;
size_t batch_length;
uint32_t checksum;
std::string batch_content;
};
It utilizes sequential I/O during it's disk writes which makes it magnitudes faster than random I/O - given that each transaction just needs to be appended, it can traverse the disk as efficiently as possible. Most modern LSMTree implementations can write WAL entries at or near disk bandwidth speeds. This means it's as efficient of an operation that can be done for this task! This does mean space amplification is 2-3x because we're storing the data on disk in SSTables, in WAL transactions, and in the MemTable, and furthermore for each transaction we store the operation so one data row with hundreds of update transactions will still have a largr storage footprint than updating the item in memory like BTree's
SSTable
-
When a MemTable is flushed to disk, you take that Sorted Run and store it on disk as an SSTable
-
i.e. when you want to write MemTable to disk, you store it as an SSTable
-
SSTables are organized into levels with max capacities of powers
- 10MB, 100MB, etc...
- Whenever any level reaches capacity, it's Compacted into next level
- This means older records will persist on disk in older SSTables until updated
-
Compaction
- Our garbage collection and data management process of our database
- Compaction takes SSTable from filled level and merges it with SSTables in next level with overlapping key ranges
- When files are merged we:
- Re-sort keys
- Outdated records are removed
- New SSTable is created
- When files are merged we:
-
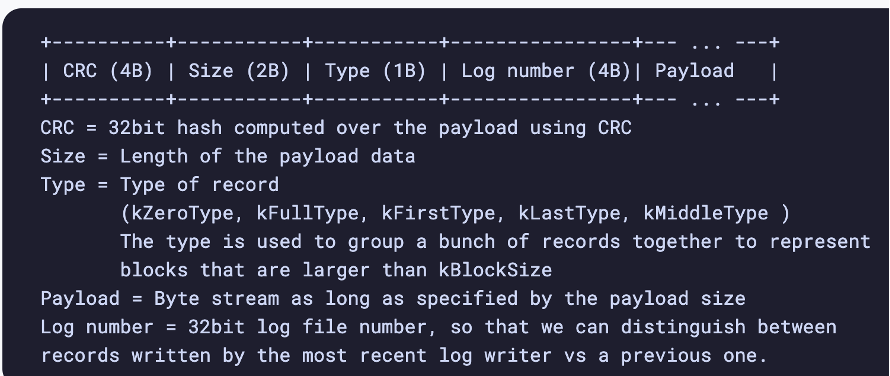
All buffered writes are lost if OS crashes
- Unbuffered I/O writes data directly to physical disk
- RocksDB has a straight append only log
- Each operation stored in a block of 32KB
- Records larger than 32KB stored in multiple blocks
- Start of block is a checksum to verify integrity
Optimizations
- Bloom Filters
- Indexing (index of index)
- B+Tree